Budowanie Skalowalnych Aplikacji Cloud-Native
Poznaj najlepsze praktyki projektowania odpornych, skalowalnych systemów cloud-native z wykorzystaniem Kubernetes, mikroserwisów i nowoczesnych praktyk DevOps.
LUSK
Opublikowano 15 kwietnia 2025
Budowanie Skalowalnych Aplikacji Cloud-Native
Systemy cloud-native są z definicji systemami rozproszonymi. Oznacza to, że nieustannie operujesz w warunkach częściowych awarii, opóźnień sieciowych oraz niespójności danych.
Celem nie jest eliminacja tych problemów — tylko zaprojektowanie systemu, który zachowuje się przewidywalnie mimo ich występowania.
Ten artykuł skupia się na praktycznych wzorcach i zasadach stosowanych w środowiskach produkcyjnych.
Podstawowe Zasady
1. Projektuj z myślą o awariach (zakładaj, że wszystko się psuje)
Awarie nie są rzadkością — są normą:
- pody są restartowane (rescheduled)
- węzły znikają
- wywołania sieciowe kończą się timeoutem
- zależności degradują się
Twój system powinien:
- szybko wykrywać awarie
- ograniczać ich zasięg (blast radius)
- automatycznie się regenerować
Przykład: retry z wykładniczym backoff + jitter (kluczowe aby uniknąć thundering herd):
1async function fetchWithRetry(url: string, maxRetries = 3): Promise<Response> {2 for (let i = 0; i < maxRetries; i++) {3 try {4 return await fetch(url);5 } catch (error) {6 if (i === maxRetries - 1) throw error;78 const delay = Math.pow(2, i) * 1000 + Math.random() * 100;9 await new Promise(resolve => setTimeout(resolve, delay));10 }11 }12}
W systemie produkcyjnym powinieneś dodatkowo mieć:
- circuit breakers (szybkie odcinanie błędnych zależności)
- timeouty na wszystkich wywołaniach
- idempotentne operacje (bezpieczne ponawianie)
- bulkhead isolation (izolacja komponentów)
2. Mikroserwisy — używaj tylko gdy mają sens
Mikroserwisy rozwiązują problemy organizacyjne, nie tylko techniczne.
Wprowadzają:
- narzut sieciowy
- problemy z transakcjami rozproszonymi
- większą złożoność operacyjną
Używaj ich, gdy potrzebujesz:
- niezależnych wdrożeń
- autonomii zespołów
- selektywnego skalowania
Twarde zasady:
- każdy serwis posiada własne dane (brak współdzielonej bazy danych)
- komunikacja przez API lub eventy (nigdy przez współdzieloną DB)
- wersjonowanie API
3. Automatyzuj wszystko (zero manualnych ścieżek)
Jeśli proces jest manualny, to:
- w końcu zawiedzie
- będzie niespójny
- blokuje skalowanie
Wszystko musi być deklaratywne i wersjonowane:
- infrastruktura
- deploymenty
- polityki
Przykład (Terraform):
1resource "google_container_cluster" "primary" {2 name = "production-cluster"3 location = "us-central1"45 initial_node_count = 367 node_config {8 machine_type = "e2-standard-4"9 disk_size_gb = 10010 }11}
Produkcyjne podstawy:
- CI/CD z mechanizmem rollback
- immutable deployments (brak zmian „na żywo”)
- Git jako źródło prawdy (GitOps)
Architektura referencyjna
Typowa architektura cloud-native oparta o Kubernetes i komunikację event-driven:
API Gateway jako punkt wejścia
mikroserwisy odpowiedzialne za konkretne domeny
broker wiadomości (np. Kafka / PubSub)
komunikacja synchroniczna + asynchroniczna
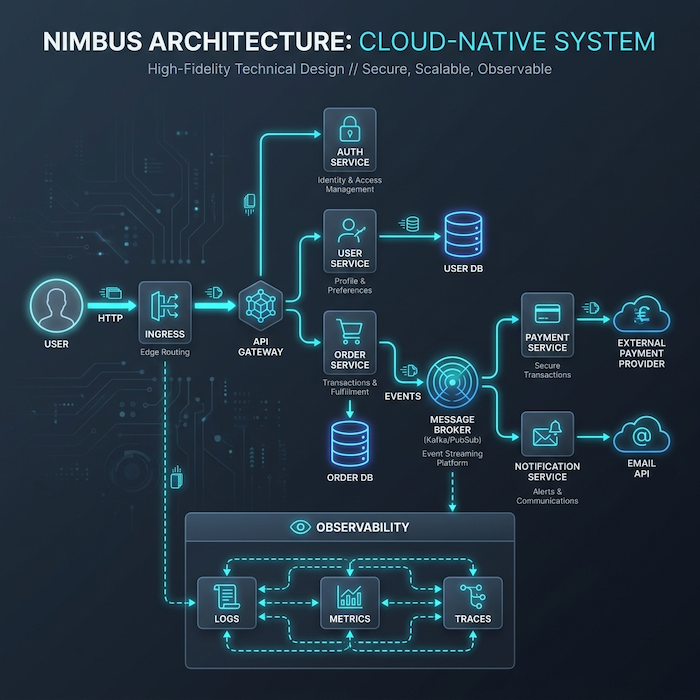
Uwagi Architektoniczne
API Gateway
- centralny punkt wejścia
- autoryzacja, rate limiting, routing
Komunikacja serwis-to-serwis
- synchroniczna (HTTP/gRPC) — prostsza, ale bardziej sprzężona
- asynchroniczna (eventy) — luźne powiązania, eventual consistency
Broker wiadomości (Message Broker)
- dekoncentruje, rozdziela system (decouples)
- umożliwia retry i buforowanie
- wprowadza opóźnioną spójność
Bazy danych
- jedna baza na serwis (ściśle wyznaczona granica)
- brak joinów między serwisami
Obserwowalność (observability) — absolutna konieczność
Bez prawidłowego monitorowania jesteś ślepy, a diagnostyka jest praktycznie niemożliwa.
Logi
- ustrukturyzowane (JSON)
- zawierają correlation ID
- brak nieograniczonych payloadów
Metryki
metoda RED:
- Rate (jak często)
- Errors (błędy)
- Duration (czas trwania)
Ślady (Traces)
- pełna ścieżka requestu przez system
- kluczowe przy debugowaniu opóźnień
Przykład:
1logrus.WithFields(logrus.Fields{2 "service": "order-processor",3 "trace_id": traceID,4 "user_id": userID,5}).Info("Order processed successfully")
Produkcyjne standardy:
- zdefiniowane SLO (nie tylko dashboardy)
- alerty oparte o symptomy (np. latency), nie metryki infrastruktury
Spójność Danych & Komunikacja
To obszar, w którym najczęściej pojawiają się błędy architektoniczne.
Unikaj Rozproszonych Transakcji
NIE polegaj na:
- 2PC (Two-Phase Commit)
- ACID między serwisami
Zamiast tego używaj:
- ostatecznej spójności (eventual consistency)
- wzorzec Saga
Przykładowy Flow (Przetwarzanie Zamówienia)
- Utworzenie zamówienia
- Publikacja eventu
- Przetwarzanie płatności
- Sukces → potwierdzenie
- Błąd → kompensacja (anulowanie)
Trade-off:
Spójność jest opóźniona ale system jest bardziej odporny
Bezpieczeństwo (Wbudowane, Nie Dodane Później)
Minimalne bazowe wymagania:
- mTLS między serwisami
- krótkotrwałe credentials
- brak "sekretów" w kodzie
- skanowanie obrazów w CI
- zasada najmniejszych uprawnień (least privilege)
Zasada zero-trust:
Każde żądanie musi być uwierzytelnione i autoryzowane, nawet wewnątrz klastra.
Co faktycznie psuje się na produkcji
Najczęstsze problemy:
- silne sprzężenie między serwisami
- brak backpressure
- brak timeoutów
- słaba obserwowalność
- zmiany schematu bez wersjonowania
Podsumowanie
Systemy cloud-native nie są definiowane przez narzędzia, ale przez sposób radzenia sobie z:
- awariami
- komunikacją
- spójnością danych
- operacjami na dużą skalę
Jeśli te aspekty są dobrze zaprojektowane — reszta (technologia) staje się łatwa i prosta w implementacji.