Building Scalable Cloud-Native Applications
Learn best practices for designing resilient, scalable cloud-native systems using Kubernetes, microservices, and modern DevOps practices.
LUSK
Published on April 15, 2026
Building Scalable Cloud-Native Applications
Cloud-native systems are distributed systems by default. That means you are constantly dealing with partial failure, network latency, and eventual consistency. The goal is not to eliminate these problems—but to design systems that behave predictably despite them.
This guide focuses on practical patterns used in real production environments.
Core Principles
1. Design for Failure (Assume Everything Breaks)
Failures are not rare events—they are continuous and unavoidable:
- pods are rescheduled
- nodes disappear
- network calls timeout
- dependencies degrade
Your system must:
- detect failure quickly
- limit blast radius
- recover automatically
Example: retry with exponential backoff + jitter (critical to avoid thundering herd):
1async function fetchWithRetry(url: string, maxRetries = 3): Promise<Response> {2 for (let i = 0; i < maxRetries; i++) {3 try {4 return await fetch(url);5 } catch (error) {6 if (i === maxRetries - 1) throw error;78 const delay = Math.pow(2, i) * 1000 + Math.random() * 100;9 await new Promise(resolve => setTimeout(resolve, delay));10 }11 }12}
In production you should also have:
- circuit breakers (fail fast)
- request timeouts everywhere (no infinite waits)
- idempotent APIs (safe retries)
- bulkheads (isolation between components)
2. Microservices: Use When Justified
Microservices are an organizational scaling tool, not just a technical one.
They introduce:
- network overhead
- distributed transactions
- operational complexity
Use them when you need:
- independent deployment
- team autonomy
- selective scaling
Hard rules:
- each service owns its data (no shared DB)
- communication via APIs/events, never DB coupling
- version your APIs
3. Automate Everything (No Manual Paths)
If a process is manual, it will:
- eventually fail
- be inconsistent
- block scaling
Everything must be declarative and versioned:
- infrastructure
- deployments
- policies
Example (Terraform):
1resource "google_container_cluster" "primary" {2 name = "production-cluster"3 location = "us-central1"45 initial_node_count = 367 node_config {8 machine_type = "e2-standard-4"9 disk_size_gb = 10010 }11}
Production baseline:
- CI/CD with rollback strategy
- immutable deployments (no in-place changes)
- Git as the single source of truth (GitOps)
Reference Architecture
Below is a typical cloud-native architecture using Kubernetes and event-driven communication:
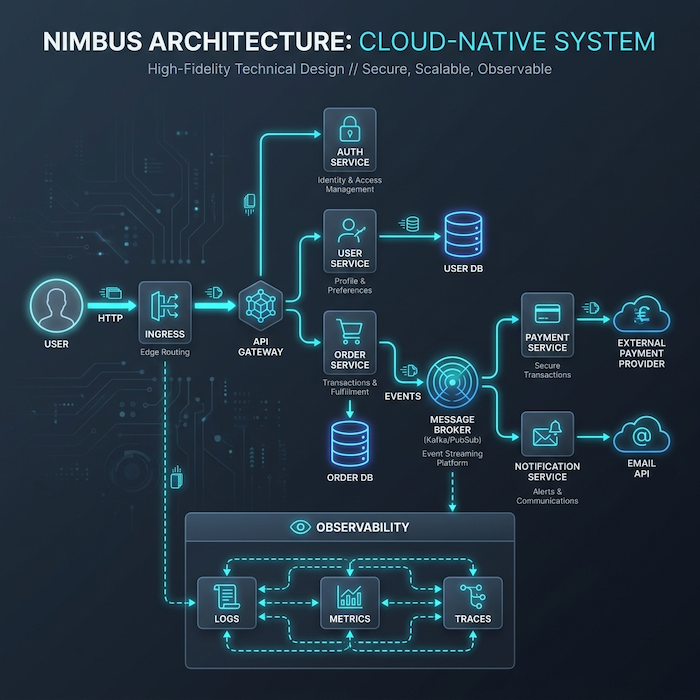
Architectural Notes
API Gateway
- central entry point
- handles auth, rate limiting, routing
Service-to-service communication
- synchronous: HTTP/gRPC (simple, but tightly coupled)
- asynchronous: events (loosely coupled, eventually consistent)
Message Broker
- decouples services
- enables retries and buffering
- introduces eventual consistency
Databases
- one per service (strict boundary)
- no cross-service joins
Observability (Non-Negotiable)
Without observability, your system is not operable.
Logs
- structured (JSON)
- include correlation IDs
- never log unbounded data
Metrics
RED method:
- Rate
- Errors
- Duration
Traces
- full request path across services
- required for debugging latency
Example:
1logrus.WithFields(logrus.Fields{2 "service": "order-processor",3 "trace_id": traceID,4 "user_id": userID,5}).Info("Order processed successfully")
Production standard:
- SLOs defined (Service Level Objectives defined not just dashboards)
- alerting based on symptoms (e.g. latency), not CPU
Data Consistency & Communication
This is where most systems fail architecturally.
Avoid Distributed Transactions
Do NOT rely on:
- 2PC (Two-Phase Commit)
- cross-service ACID
Instead use:
- eventual consistency
- Saga pattern
Example Flow (Order Processing)
- Order created
- Event emitted
- Payment service processes
- Success → confirm order
- Failure → compensate (cancel)
Trade-off:
Consistency is delayed but system becomes resilient
Security (Built-In, Not Added Later)
Minimum baseline:
- mTLS between services
- short-lived credentials
- secrets not stored in code
- image scanning in CI
- least privilege IAM
Zero-trust principle:
Every request must be authenticated and authorized, even inside the cluster.
What Actually Breaks in Production
From real-world systems, the biggest issues are:
- tight coupling between services
- lack of backpressure handling
- missing timeouts
- poor observability
- schema changes without versioning
Conclusion
Cloud-native systems are not defined by tools like Kubernetes—they are defined by how you handle:
- failure
- communication
- data consistency
- operations at scale
If you get those right, the technology stack becomes easy and straightforward.